This is a guest post by Serhii Kushchenko, Python/Django developer and data analyst. He is skillful in SQL, Python, Django, RESTful APIs, statistics, and machine learning.
This post aims to demonstrate the creation and processing of the large and complex form in Django using django-crispy-forms. The form contains several buttons that require executing different actions during the processing phase. Also, in the form, the number of rows and columns is not static but varies depending on some conditions. In our case, the set of rows and columns changes depending on the number of instances (columns) associated with the main object (data schema) in a many-to-one relationship.
The django-crispy-forms documentation includes a page Updating layouts on the go. That page is quite helpful. However, it does not contain any detailed example of a working project. IMHO such an example is much needed. I hope my project serves as a helpful addition to the official Django Crispy Forms documentation. Feel free to copy-paste the pieces of code that you find applicable.
Please see the full codebase here. It is ready for Heroku deployment.
Task
Suppose we have a database with information about people: name, surname, phone numbers, place of work, companies owned, etc. The task is not to process the data but to work with meta-information about that data.
Different users may need to extract varying information from the database. These users do not want to write and run SQL queries. They demand some simple and more visual solutions. The assignment is to make it possible for users to create the data schemas visually. In other words, to develop such a form and make it fully functioning.
Using their schemas, users will be able to CRUD data in the database. However, these operations are beyond the scope of the current project.
Different columns can have their specific parameters. For example, integer columns have lower and upper bounds. It is necessary to develop functionality for editing those parameters for all types of columns. For that editing, forms are used that arise after clicking the "Edit details" button on the main form.
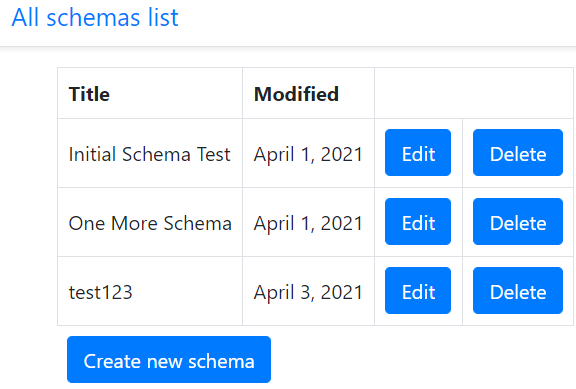
Moreover, we have to develop a form "Create new schema" and a page with a list of all available schemas.
Solution
Described below:
- Data models used.
- How the required forms are generated.
- Recognizing and handling the user-initiated state changes.
The task described above can be better solved using JavaScript together with Django forms. It would reduce the number of requests to the server and increase the speed of the application. So the user experience would improve. However, the project aimed to create an advanced example of working with Django Crispy Forms.
Here you can learn the following tricks:
- Compose a complex Django Crispy Form using the Layout, Row, Column, Fieldset, Field, and other available classes.
- During form generation, iterate over the Foreign Key related objects and create a form row for each of them.
- When it makes sense to use an abstract base class and when it doesn't.
- How to encode the required action and other data in the button name during its creation.
- Determine which button the user clicked and implement the analog of switch-case statement to perform the required action.
- Automatically populate the newly generated form with the request.POST data if you want and if that data is available.
- Validation of user-entered data (phone number) using a regular expression.
- If you have many similar models, use metaprogramming to generate ModelForm classes for those models without violating the DRY principle.
Models
According to the task, the number of columns in the schemas can be different. The users add new columns and delete existing columns. Also, they can change the type and order of columns. The columns and schemas have a many-to-one relationship that is described using the Foreign Key in Django models.
The picture shows that every schema has its name, 'Column separator' field, and 'String character' field. Also, it would be nice to save the date of the last schema modification. The following code from schemas\models.py file is pretty simple.
INTEGER_CH = "IntegerColumn"
FULLNAME_CH = "FullNameColumn"
JOB_CH = "JobColumn"
PHONE_CH = "PhoneColumn"
COMPANY_CH = "CompanyColumn"
COLUMN_TYPE_CHOICES = [
(INTEGER_CH, "Integer"),
(FULLNAME_CH, "Full Name"),
(JOB_CH, "Job"),
(PHONE_CH, "Phone"),
(COMPANY_CH, "Company"),
]
DOUBLE_QUOTE = '"'
SINGLE_QUOTE = "'"
STRING_CHARACTER_CHOICES = [
(DOUBLE_QUOTE, 'Double-quote(")'),
(SINGLE_QUOTE, "Single-quote(')"),
]
COMMA = ","
SEMICOLON = ";"
COLUMN_SEPARATOR_CHOICES = [(COMMA, "Comma(,)"), (SEMICOLON, "Semicolon(;)")]
class DataSchemas(models.Model):
name = models.CharField(max_length=100)
column_separator = models.CharField(
max_length=1,
choices=COLUMN_SEPARATOR_CHOICES,
default=COMMA,
)
string_character = models.CharField(
max_length=1,
choices=STRING_CHARACTER_CHOICES,
default=DOUBLE_QUOTE,
)
modif_date = models.DateField(auto_now=True)
def get_absolute_url(self):
return reverse("schema_add_update", args=[str(self.id)])
Each column has a name, type, and order. All of these fields are in the base SchemaColumn(models.Model) class. This class cannot be abstract because in such a case, the code schema.schemacolumn_set.all() would not work.
Columns of type integer, first and last name, job, company, and phone number are implemented as classes derived from the base class SchemaColumn.
class SchemaColumn(models.Model):
name = models.CharField(max_length=100)
schema = models.ForeignKey(DataSchemas, on_delete=models.CASCADE)
order = models.PositiveIntegerField()
class Meta:
unique_together = [["schema", "name"], ["schema", "order"]]
def save(self, *args, **kwargs):
self.validate_unique()
super(SchemaColumn, self).save(*args, **kwargs)
class IntegerColumn(SchemaColumn):
range_low = models.IntegerField(blank=True, null=True, default=-20)
range_high = models.IntegerField(blank=True, null=True, default=40)
class FullNameColumn(SchemaColumn):
first_name = models.CharField(max_length=10, blank=True, null=True)
last_name = models.CharField(max_length=15, blank=True, null=True)
class JobColumn(SchemaColumn):
job_name = models.CharField(max_length=100, blank=True, null=True)
class CompanyColumn(SchemaColumn):
company_name = models.CharField(max_length=100, blank=True, null=True)
class PhoneColumn(SchemaColumn):
phone_regex = RegexValidator(
regex=r"^\+?1?\d{9,15}$",
message="Phone number must be entered in the format: '+999999999'. Up to 15 digits allowed.",
)
phone_number = models.CharField(
validators=[phone_regex], max_length=17, blank=True, null=True
) # validators should be a list
Forms
The schema editing form is quite complex. We do not use the Django built-in ModelForm class here because it is not flexible enough. Our class DataSchemaForm is a derivative of the forms.Form class. Of course, django-crispy-forms was very helpful and even essential.
from crispy_forms.layout import (
Layout,
Submit,
Row,
Column,
Fieldset,
Field,
Hidden,
ButtonHolder,
HTML,
)
The type of column in the form depends on the class of the column. How to determine that class? The problems can arise if we use the built-in isinstance() function for derived classes such as our various column types. The following code demonstrates how the subclass check was implemented in the forms.py file when generating the form.
INTEGER_CH = "IntegerColumn"
FULLNAME_CH = "FullNameColumn"
JOB_CH = "JobColumn"
PHONE_CH = "PhoneColumn"
COMPANY_CH = "CompanyColumn"
COLUMN_TYPE_CHOICES = [
(INTEGER_CH, "Integer"),
(FULLNAME_CH, "Full Name"),
(JOB_CH, "Job"),
(PHONE_CH, "Phone"),
(COMPANY_CH, "Company"),
]
subclasses = [
str(subclass).split(".")[-1][:-2].lower()
for subclass in SchemaColumn.__subclasses__()
]
# yes, somewhat redundant
column_type_switcher = {
"integercolumn": INTEGER_CH,
"fullnamecolumn": FULLNAME_CH,
"jobcolumn": JOB_CH,
"companycolumn": COMPANY_CH,
"phonecolumn": PHONE_CH,
}
column_type_field_name = "col_type_%s" % (column.pk,)
self.fields[column_type_field_name] = forms.ChoiceField(
label="Column type", choices=COLUMN_TYPE_CHOICES
)
for subclass in subclasses:
if hasattr(column, subclass):
self.fields[column_type_field_name].initial = [
column_type_switcher.get(subclass)
]
break
How new schemas are created
The function that generates the schema editing form may get the primary key of the existing schema. If such a key is not available, then the function creates a new schema and its first column. After that, the user can change the parameters of the schema, as well as add new columns.
if schema_pk:
schema = DataSchemas.objects.get(pk=schema_pk)
else:
# no existing schema primary key passed from the caller,
# so create new schema and its first column
# with default parameters
schema = DataSchemas.objects.create(name="New Schema")
int1 = IntegerColumn.objects.create(
name="First Column",
schema=schema,
order=1,
range_low=-20,
range_high=40,
)
self.fields["name"].initial = schema.name
self.fields["column_separator"].initial = schema.column_separator
self.fields["string_character"].initial = schema.string_character
In addition to the schema editing form, the application also contains a list of all created schemas.
There is nothing special about that page, so I will not describe it in detail here. Pleas see the full code and templates at https://github.com/s-kust/django-advanced-forms.
Requests processing
The picture shows that the schema editing form contains several types of buttons:
- Submit form
- Add new column
- Delete column
- Edit column details
We need to determine which button the user pressed and perform the required action.
During the form creation, the required action is encoded in the names of all the buttons. Also, the column primary key or schema primary key is encoded there. For example, delete_btn = 'delete_col_%s' % (column.pk,) or submit_form_btn = 'submit_form_%s' % (schema.pk,).
The name of the button can be found in the request.POST data only if the user has pressed that button. The following code from the views.py file searches for the button name in the request.POST data and calls the required function. A well-known method is used to implement the Python analog of switch-case statement.
btn_functions = {
"add_new_col": process_btn_add_column,
"delete_col": process_btn_delete_column,
"edit_col": process_btn_edit_column_details,
"submit_form": process_btn_submit_form,
"save_column_chng": process_btn_save_chng_column,
}
btn_pressed = None
# source of key.startswith idea - https://stackoverflow.com/questions/13101853/select-post-get-parameters-with-regular-expression
for key in request.POST:
if key.startswith("delete_col_"):
btn_pressed = "delete_col"
if key.startswith("edit_col_"):
btn_pressed = "edit_col"
if key.startswith("add_column_btn_"):
btn_pressed = "add_new_col"
if key.startswith("submit_form_"):
btn_pressed = "submit_form"
if key.startswith("save_column_chng_btn_"):
btn_pressed = "save_column_chng"
if btn_pressed is not None:
func_to_call = self.btn_functions.get(btn_pressed)
self.pk, form = func_to_call(self, key, form_data=request.POST)
break
Editing parameters of different types of columns
Different types of columns have their specific parameters. For example, integer columns have lower and upper bounds. Phone columns have the phone number field that requires validation before saving. The number of different types of columns can increase over time.
How to handle the Edit Details button click? The straightforward solution is to make individual ModelForm classes for each type of column. However, it would violate the DRY principle. Perhaps, in this case, the use of metaprogramming is justified.
def get_general_column_form(self, model_class, column_pk):
class ColumnFormGeneral(ModelForm):
def __init__(self, *args, **kwargs):
super(ColumnFormGeneral, self).__init__(*args, **kwargs)
self.helper = FormHelper(self)
save_chng_btn = "save_column_chng_btn_%s" % (column_pk,)
self.helper.layout.append(Submit(save_chng_btn, "Save changes"))
class Meta:
model = model_class
exclude = ["schema", "order"]
return ColumnFormGeneral
First, the type of column is determined using its primary key. After that, the get_general_column_form function is called. It returns the customized ModelForm class. Next, an instance of that class is created and used.
column = get_object_or_404(SchemaColumn, pk=column_pk)
for subclass in self.subclasses:
if hasattr(column, subclass):
column_model = apps.get_model("schemas", subclass)
column = get_object_or_404(column_model, pk=column_pk)
form_class = self.get_general_column_form(column_model, column_pk)
form = form_class(
initial=model_to_dict(
column, fields=[field.name for field in column._meta.fields]
)
)
break
Handling of the column type change
The user may change the type of one or several columns. If it happens, it means that the class of these columns has changed. Here, it is not enough to change the value of some attribute of the object. We have to delete the old object and create a new object belonging to the new class instead. How do we handle it:
- First, a form is generated using the schema's primary key.
- Then, in the newly created form, the data from the database is replaced with the request.POST data, if that data is available. It happens automatically.
- In the next step, the form is validated. For that, we have to call the
form.is_valid() method explicitly.
- If the validation is successful, then we process every column of the schema. For each column, its type from the database is compared with its type from the form. It means that its database type is compared with its
request.POST type. If these types differ, the old column is deleted, and a new one is created instead.
# elem is a 'Submit Form' button that the user pressed.
# schema primary key is encoded in its name
# first, let's decode it
self.pk = [int(s) for s in elem.split("_") if s.isdigit()][0]
# form_data is request.POST
form = DataSchemaForm(form_data, schema_pk=self.pk)
if form.is_valid():
schema = get_object_or_404(DataSchemas, pk=self.pk)
schema.name = form.cleaned_data["name"]
schema.column_separator = form.cleaned_data["column_separator"]
schema.string_character = form.cleaned_data["string_character"]
schema.save()
# the following code is in the save_schema_columns(self, schema, form) function
schema_columns = schema.schemacolumn_set.all()
for column in schema_columns:
column_name_field_name = "col_name_%s" % (column.pk,)
column_order_field_name = "col_order_%s" % (column.pk,)
column_type_field_name = "col_type_%s" % (column.pk,)
type_form = form.cleaned_data[column_type_field_name]
type_changed = False
for subclass in self.subclasses:
if hasattr(column, subclass):
type_db = self.column_type_switcher.get(subclass)
if type_db != type_form:
new_class = globals()[type_form]
new_column = new_class()
new_column.name = form.cleaned_data[column_name_field_name]
new_column.order = form.cleaned_data[column_order_field_name]
new_column.schema = schema
column.delete()
new_column.save()
type_changed = True
break
if not type_changed:
column.name = form.cleaned_data[column_name_field_name]
column.order = form.cleaned_data[column_order_field_name]
column.save()
Final Words
I hope this post serves as a helpful addition to the official Django Crispy Forms documentation. Feel free to copy-paste the pieces of code that you find applicable. Also, write comments and share your experience of using Django Crispy Forms.
Cover photo by Juan Pablo Malo.